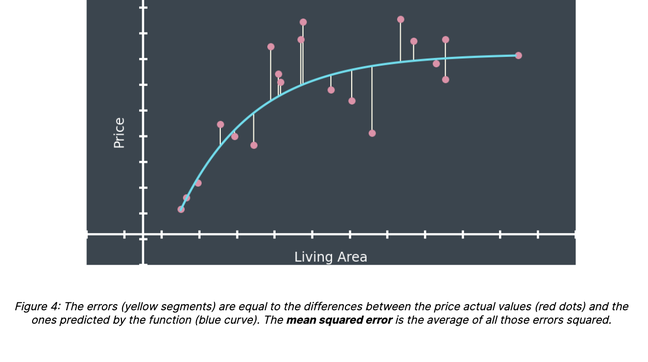
At PriceHubble, we work at providing the best tool on the market for real estate property valuation. To do so, we develop what is usually referred to as Automated Valuation Models (AVM). The purpose of an AVM is, given a set of property characteristics, such as the location, the living area, or the floor number, to return the most accurate price estimate for this property.
In this article, we explain how Regression Splines can be useful to effectively build such systems.
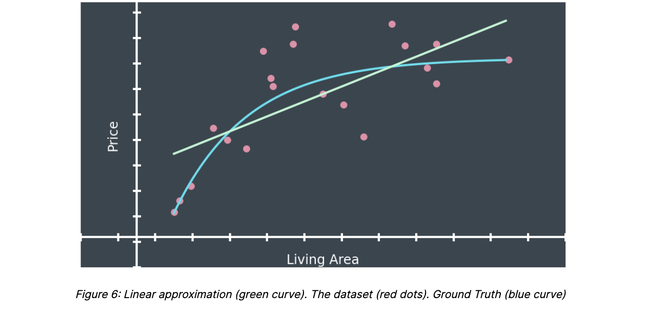
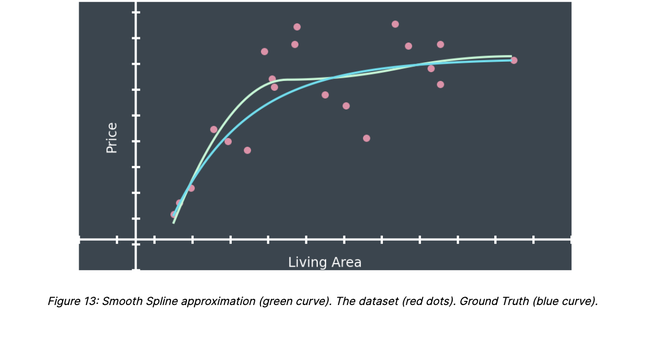
Ground Truth
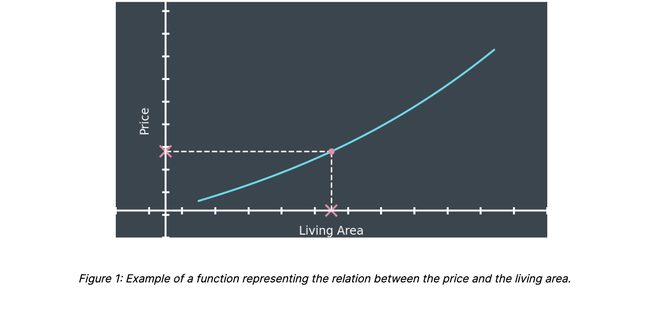
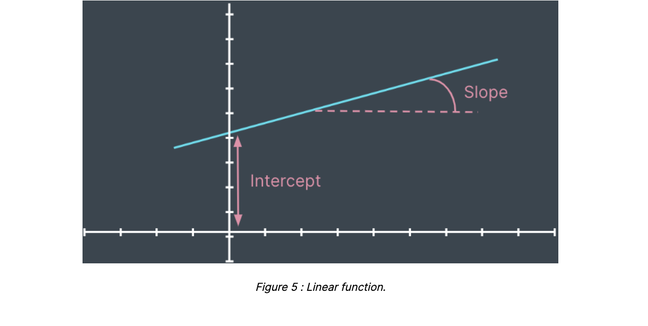
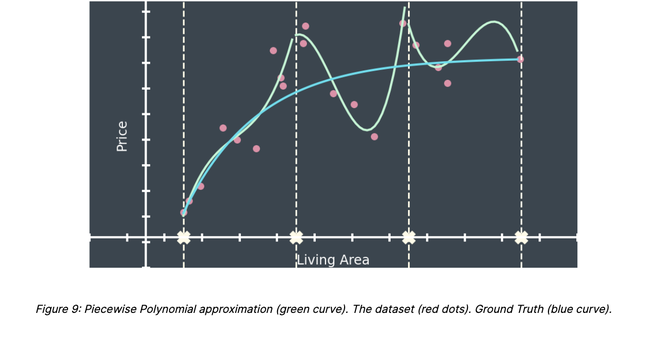
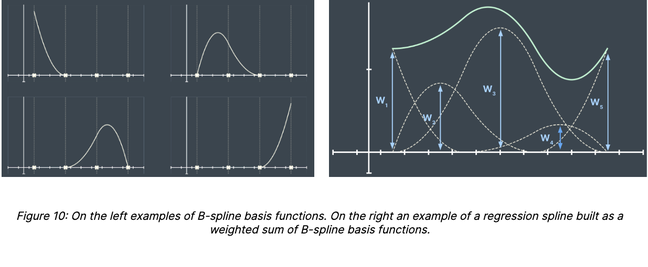
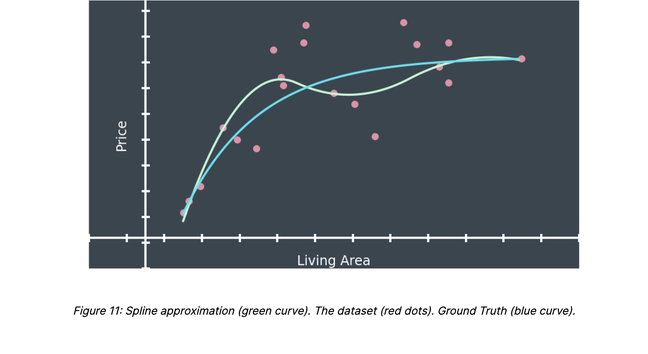
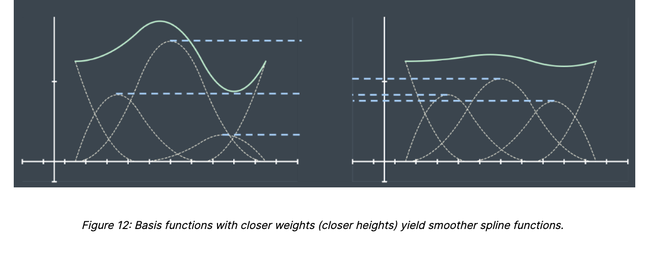
For the sake of simplicity, we consider the problem of estimating the price of a property given its living area. In that case, the AVM can be mathematically represented by a function; i.e. a mapping matching every possible value of the living area to a unique price estimate (figure 1).